My name is Adrian Filip and I have been a software developer since 2007.
Sometime in between then and now I was working on a banking like app using Kotlin, SpringBoot and Arrow.
Everything was going well but yet I was finding it difficult to express some scale aspects without either mucking up my business a bit or trading away some composability by using infrastructure layer more. (See my previous post Why modularity? to understand why I abhor lack of composition in designs & implementations).
As a result I took it upon myself to improve the DDD model* by adding a layer that is all about scale concerns and keeping the business and infrastructure layers untouched by this scale corruption**. (If you want to learn more about DDD I highly recommend to go to the source Vaughn Vernon’s books.) If you are familiar with DDD and from what I wrote so far you might have guessed it that I’m in the Onion Architecture camp. (Don’t be fooled by the name, unlike the vegetable, in this case not using it will make you cry.)
How does this new Onion looks like? Something like this.
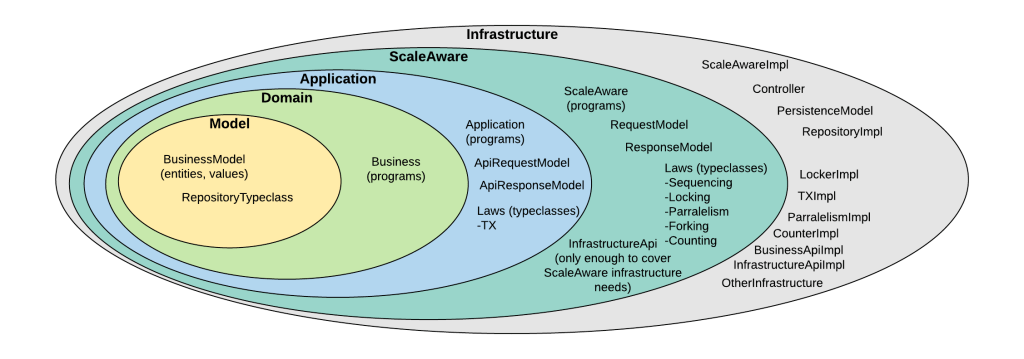
Where you see the term program it means the description of a program. Remember that we want composability so we are working with descriptions of programs, which are values.
Why did I add that new layer for that application? Maybe the next picture will clarify it a bit.
(NOTE: ScaleAwareAPI, API, InfrastructureAPI and DomainRepository are traits only, not typeclasses – will update the picture soon)
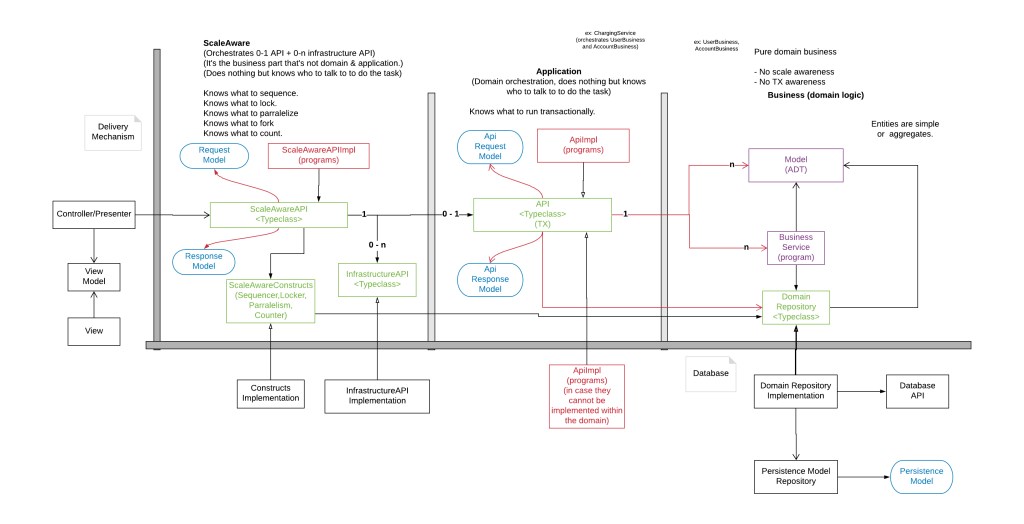
I added the ScaleAware layer because I wanted:
- to free up the business (domain and orchestration) from knowing non business details (cleanups, paralelisation concerns, monitoring concerns). I also consider notions like what can be paralellized or what must be performed in sequence not truly “dumb piping” parts of the infrastructure.
- a layer where I can control how inevitable infrastructure operations (like cleanup or archive old backups) & business operations interact
- a layer where the business like aspects that can see into the dimension of scale can be defined. Unlike the Application layer that can only orchestrate business programs or Business layer where the entire universe of a business service only knows about work with certain types of entities. Or the infrastructure layer that is the one that actually knows how what is out there, beyond the domain works
There are some basic guidelines (read as mandatory rules) associated with this model:

- 1 Scale Aware operation = 1 Scale Aware program = 1 business use case + related scale aware aspects
- ScaleAware programs don’t call other ScaleAware programs and are not aware of them.
- 1 Application operation = 1 Application program = 1 business use case
- Aplication programs never call other application programs and are not aware of them. Common parts are reused via business programs.
- Business programs never fork. That concept is only present in the scaleaware level.
- Also each construct will have its own rules. For instance:
- the Transactor construct that has the api TX.tx(program) can only work with non forking IO’s. Everything else is a misuse
- the Parallelism & Forking constructs must be provided the proper thread pools for their purpose …
- All calls go through scale aware and API regardless of what happens there.
- Why?
- Control – To have a clear and complete API boundary
- Flexibility – To easily enhance the program when needed
- Why?
(Example of an infrastructure service:A BackupService interface with a method called backup (the interface just has that operation and the impl will be the one that handles the details of what that actually means for this app. So the scale aware concern of creating a backup can be defined at the scale aware level via the interface. ) The impl can backup a nosql or a rdbms or a file and can do it in a whatever infrastructurally decided way. But this step can still be encoded in the scale aware instructions. It’s just that how it is implemented is pushed to the infrastructure layer, outside of scale aware’s clean api.)
But the actual power of the ScaleAware layer is given by the constructs that it uses. For example:
The Laning constructor provides a way to sequence the execution of whatever programs you want based on a dynamic definition of the “lanes” it needs open to run.
An analogy that would describe it is:
Imagine it like you have a highway with n lanes and each car is magic and can somehow use whatever1 or more lanes it wants at the same time. But they can only pass the toll booth only if all the lanes they use are free.
Lanes: 1 2 3 4 5
Car 1: x x
Car2: x
Car 3: x x
Car 4: x x
The way the cars above pass the toll booth is:
– Car 1 and Car 2 reach the toll booth because their lanes are free
– Car 2 is queued up behind Car 1
– Car 4 is queued up behind cars 2 and 3, so until they both pass the booth it just has to wait.
The biggest increase in productivity on this project came when I switched it to FP. The next boost was defining the scale aware architecture. Using Arrow FP + ScaleAware made the cost of maintenance and developing new features drop by a lot.
But that was then. Since then I noticed that the Scala world did not stop innovating despite the great flame wars of the 2010s***. One of the results of that innovation is a library called ZIO.
I have been using ZIO almost exclusively for about a year now and I am so impressed by it that I really want to see how my ScaleAware project would look like implemented in ZIO.
I think I will start the migration by comparing the implementations of one of my constructs between:
Arrow + Kotlin + Reactor + Future vs ZIO + Scala.
Place your bets!
* No DDD models were harmed in the design of the ScaleAware architecture.
**I sometimes use hyperbole. Not here, but I sometimes do.
*** Many were raised to Olympus (went to Haskell, some say they still describe how to drink nectar but never do it), some deserted (to Kotlin), I strategically retreated to Kotlin (next question please) and others started raising llamas or smth

One thought on “Scale Aware Architecture (Onion Arch. with a twist)”