Several years ago, I was developing an application that dealt with money. It handled loans, deposits, monthly payments, and reports. Unlike other apps, where eventual consistency and stale data may not be an issue, here one slip could lead to financial ruin for the company.
Computing the distribution of a client payment depended on a huge number of factors, including the accounts, the current customer rank, the current personalized interests established with the company, the current global rates, the client loan status, and sometimes other factors!
I was terrified just contemplating the ways in which the application could go wrong, most due to race conditions:
- What if any of those factors change, as the distribution is computed?
- What if the customer forgot their spouse said they will make the payment when the office opens, so they now make the payment together at the same time from different offices?
- What if the operational costs change because the manager corrected for inflation (or some other reason) at the same time as the payment is made?
- What if the client rank gets increased because of promotion at the time of the client payment?
- What if the client and their spouse both want to liquidate the same deposit at the exact same time at two different offices?
There’s a potential for many things to go wrong, including the dreaded double-spend!
If you’ve read my Scale Aware Architecture article, you may remember that I mentioned my solution to this problem in Kotlin, Spring Reactor, and Arrow: a novel MultiLaneSequencer concurrency structure, designed precisely to solve my problem.
The MultiLaneSequencer allows you to enforce at runtime the order in which all received requests are processed, with user-specified guarantees on what is permitted to be concurrent, and what is required to be sequential.
MultiLaneSequencer allows us to handle concurrent and sequential requests across different lanes.
Given the following lanes and requests:
Lanes: 1 2 3 4
t0 Request 1: X X
t1 Request:2 X
t2 Request 3: X X
t3 Request 4: X X
where t0 < t2 < t3 < t4
The order in which the requests above are processed is:
- Request 1 and Request 3 can be processed concurrently because their lanes are free
- Request 2 is queued up behind Request 1
- Request 4 is queued up behind Request 2 and Request 3, so until they are both processed it just has to wait in a non-blocking fashion (it should not block threads, but should wait asynchronously).
This requires tricky logic to get right, with severe consequences for any bugs—bugs that will themselves be tricky to find!
In the rest of the article, I will show you the Kotlin solution I came up with at that time, and then compare it with the Scala + ZIO solution I have since switched to.
The Kotlin Solution
First of all, my external API would be a function that has as input parameters a Set<Lane> and a program (IO<A>) and returns an IO<CompletableFuture<A>> which is a description of a program that does the same thing but this time it does it in a laning context. I return a program that describes an async effect in a laning context.
The external API looks like this:

After some false starts and throwaway code, I came up with the following solution:
- A requestResponseEventBus where the requests are published and from which responses are consumed
- A sequential consumer of requestResponseEventBus that
- In case it receives RequestMessages, it either puts them in a sequential pending state, or publishes them to requestsEventBus.
- In case it receives ResponseMessages, it checks if there were any requests waiting for this one to finish, and if there were and they are now eligible for processing, they will be published to requestsEventBus.
- A requestsEventBus for RequestMessage(s) – effects that are ready to be executed are published here
- A parallel consumer of requestsEventBus, which executes the program in the consumed request and then publishes the RequestResponse in the requestResponseEventBus
Based on this description, I created a model for a Message sum type:
- One term for requests
- One term for response

Then I created a sum type for Lane:
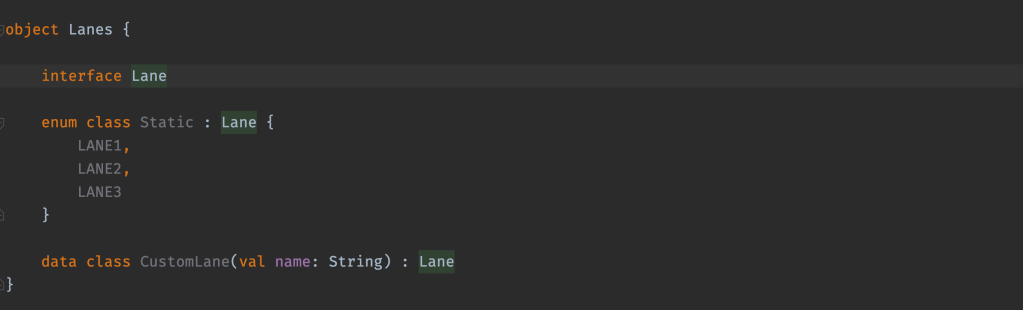
Notice here that you can define lanes at whatever granularity you want. For instance: One lane can be CLIENTS so all operations on clients are sequential, but it can also be for a specific Client “data class CustomLane(val name: String): Lane” so you can have multiple operations that even though if they are on the same client should be sequential, they can be performed in parallel for different clients.
Now that I have the event bus and a functional data model, let’s see what the implementation looks like.
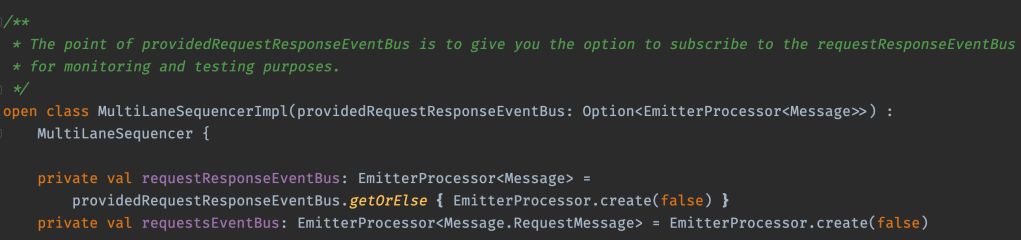
I use two event buses, one for request/responses, and one for requests, with an option for testing:
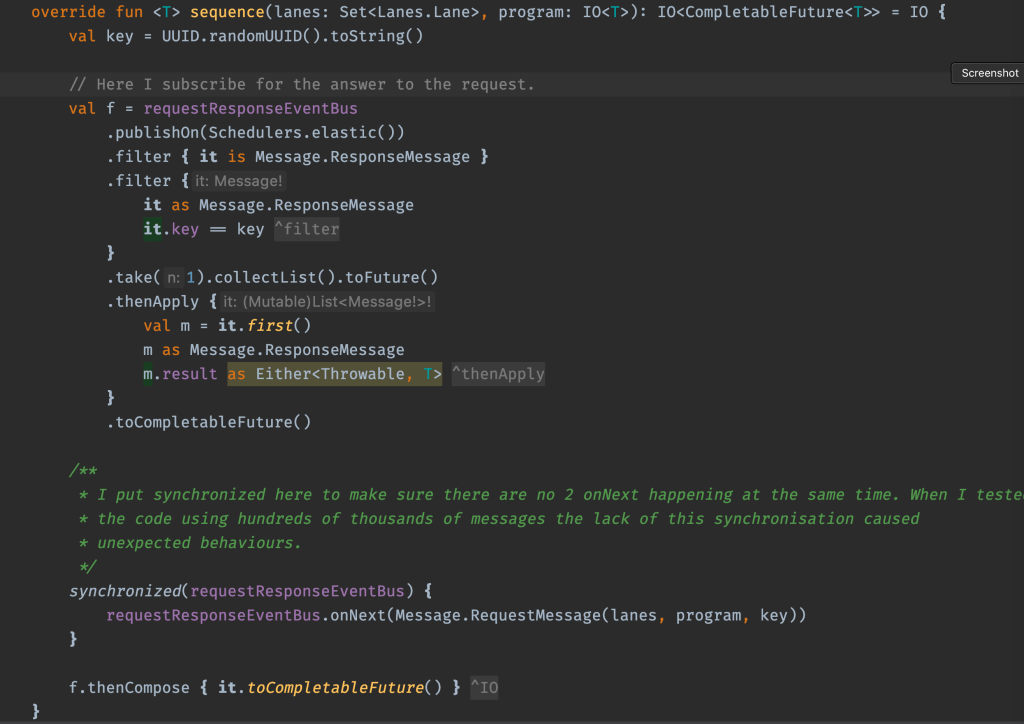
The sequence implementation is implemented as follows:
I subscribe to the requestResponseEventBus bus for the result. Then I publish the request to it. Note that subscribe – publish must be done in this precise order, otherwise the result may already be provided by the time the subscriber is initialised!
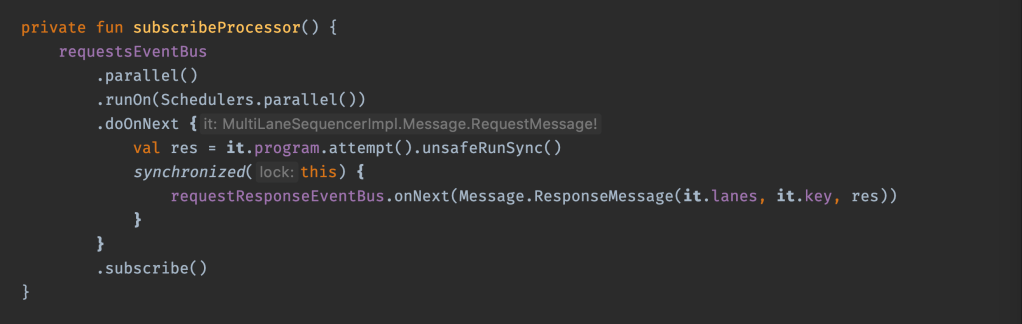
That was easy enough. How about subcribeProcessor, the parallel consumer of requestsEventBus, which executes the program in the consumed request, and then publishes the RequestResponse in the requestResponseEventBus?
This one is implemented as follows:
The sequential consumer is implemented as follows:

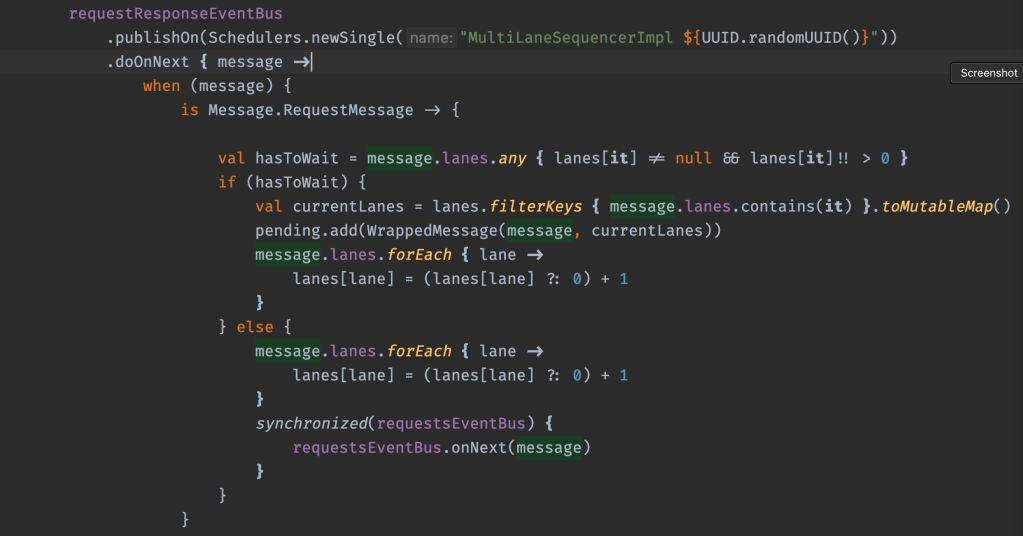


Where:

Testing the Kotlin Solution
The trickiest part of the Kotlin solution was figuring out how to test it—creating a realistic test environment and a correct check. Considering the nature of the problem, the test would need to check that the responses distribution and order on the lanes matches the requests distribution and respects their global ordering.
Think about it like the horseshoe game: If I throw blue, red, and then yellow, then when I check the pike, I should only see blue, red, yellow—any other combination would represent a failure.
At the time, I tested the code with several orders of magnitude more concurrency than expected real world usage. I did not push further, but there’s no reason why this wouldn’t hold for more concurrency.
The tests I developed, along with the implementation, can be found in the Github repository, also linked at the end of this article.
Why Scala?
Until recently, Kotlin + Spring + Reactor + Arrow seemed unbeatable as my “go to” choice for creating new applications. That stack has a great language (Kotlin), has the tooling (IntelliJ), has a powerful library for creating reactive applications (Spring Reactor), has an answer for functional programming (Arrow) and has a great and big community behind it. You can trust it.
Then in 2018, I noticed the IO[E, A] effect from John De Goes. Over time, this effect turned into ZIO[R,E,A] and a great community grew around the data type, along with rapid development of an ecosystem.
About a year ago, I switched to ZIO for new projects. Since then, I have looked at some of my old projects, and migrating some of them to Scala + ZIO.
One of those is the MultiLaneSequencer construct.
As you may have noticed, the Kotlin + Spring Reactor + Arrow solution is not necessarily easy or simple. Also as you can see, it’s not fully functional, which limits composability and hampers testability.
Could Scala + ZIO provide a simple and pure functional version?
Let’s find out!
ZIO 101
ZIO provides a data type called “ZIO[R, E, A]” that represents a whole asynchronous, concurrent workflow, which can be run in some environment of type R, might error with some value of type E, and will (hopefully) succeed with a value of type A.
Values with this type are called ZIO effects, and ZIO effects compose in a type safe fashion with other ZIO effects, allowing us to build up big programs out of simple pieces.
ZIO is built on next-generation asynchronous fibers, which allow high-performance and high scalability, without any blocking. ZIO is also packed with data structures that make it easier to build concurrent applications, like async queues, semaphores, and promises.
The most powerful tool in ZIO for building concurrent structures is STM. STM, which stands for Software Transactional Memory, allows building up transactions over shared state. Different fibers can commit different transactions to the same shared state at the same time, and ZIO ensures they are executed with the “ACID” guarantees that databases provide (but without the ‘D’, “durability”).
Because STM is composable and purely functional, it means you can build up larger concurrent structures from smaller ones. Because STM is declarative, it means you never need to use locks or other low-level primitives that are deadlock prone. All STM code is automatically purely asynchronous, and can be safely canceled for timeout purposes.
The Scala Solution
What would a solution that uses STM look like?
For Lane, there wouldn’t be much of a difference besides the syntax that Scala requires for constructing sum types:

The API for the MultiLaneSequencer still defines an operation that receives a set of Lanes, but the effect being executed and returned is now a ZIO effect:

Note that randomness in generating a globally-unique identifier (a side effect) is also removed by passing the effect id as a parameter:
The implementation I came up with relies heavily on the transactional guarantees of STM:
- When the MultiLaneSequencer is created, I create a laning map (as a transactional map). This map will be used right before and after an effect is executed, to maintain global ordering.
- When creating the sequencer, I allow an Option[Recorder], which will be None in production scenarios and Some when testing. When the Recorder is present, it is used to record requests and responses for testing purposes. You can ignore it when looking at the code.
- Then, when an effect is sequenced, an occupyLanes effect is created that updates the laning map by adding the global identity.
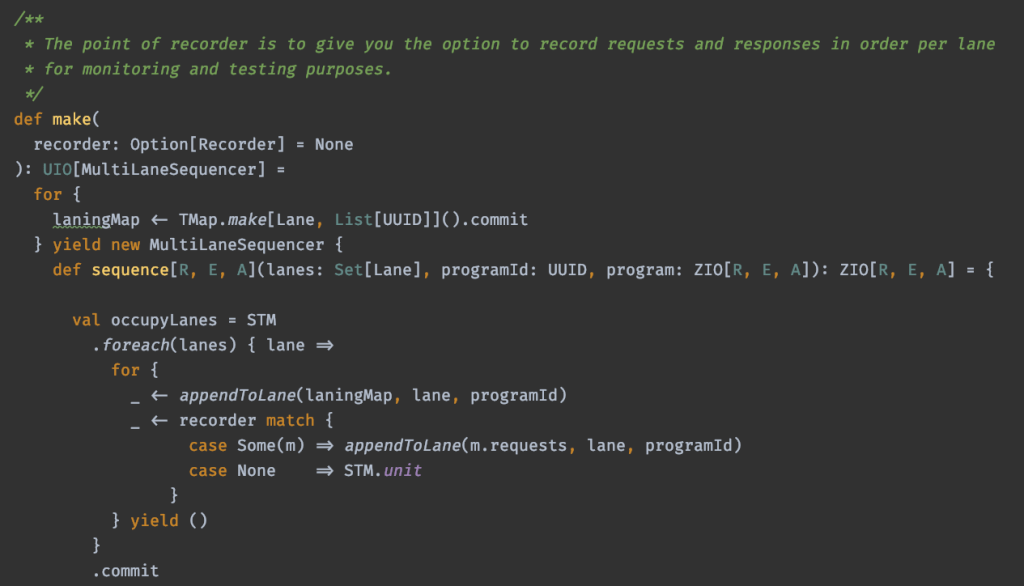
- The waitUntillFree effect succeeds when the effect being executed is next in line to be processed for all of the lanes it occupies; or, it asynchronously waits and retries when the laningMap is updated.
- The release effect removes all information about the program from the laningMap.
- With all those pieces, the solution becomes:
- update laning map
- Wait until next in line, execute the effect, and then cleanup
- This part uses bracket, which is a method that guarantees that the release is always performed (it’s like try / finally).

There you have it, the full solution in Scala + ZIO—just a few lines of declarative and type-safe code.
I couldn’t believe the ZIO STM solution is this straightforward!
Testing the Scala Solution
The test for the ZIO solution flowed naturally from the implementation. I was surprised by how composable testing can be and how much control you could have over all aspects, including passage of time.
Unlike the Kotlin+Spring Reactor+Arrow tests, the solution where I have control of effects to this high of a degree made reasoning and testing much easier for me in Scala + ZIO.
Bonus: MultiLaneLocker
A cool thing about the composability of STM and functional programming is that if you rearrange the pieces or remove one, you can still build something useful!
For instance, if I remove the sequentiality part from MultiLaneSequencer, I will have a new construct, let’s call it MultiLaneLocker, which allows me to control concurrent execution based on lanes, but provides no global ordering guarantees.
Practically speaking, this means that given the following situation:
L – lane
P – program
L1 L2 L3 L4
t0 P1 X X
t1 P2 X
t2 P3 X X
t3 P4 X X
t0 < t1 < t2 < t3
MultiLaneLocker guarantees that:
– P1 – P2 – P4 will run one at a time
– P3 – P4 will run one at a time
but it makes no guarantees about the order in which they run.
This solution is just a subset of the first solution:

Conclusions
When it comes to solving real world tricky concurrency problems, there is no doubt Kotlin + Spring Reactor + Arrow allows you to build asynchronous and functional solutions.
Yet it is also clear from this example that the Scala + ZIO solution is way simpler and was written faster. The Scala + ZIO solution is easier to test, easier to compose, and easier to understand, and can be quickly tweaked to generate new variations for changing requirements.
Next time I need to solve a tricky problem, I’ll reach for Scala + ZIO, because the cost of solving these problems is much lower. I recommend any readers who have concurrency challenges on the JVM to check out ZIO STM before using what you already know.
You can find the code & tests for both Scala and Kotlin solutions on my GitHub:
Thanks John De Goes and Adam Fraser for greatly accelerating my understanding of ZIO STM and ZIO Test.
You can also find me on:
